
 Remember that scene in Prometheus when David, the ship’s AI, was studying ancient languages in the hopes of being able to speak to the Engineers? The logic here was that since the Engineers were believed to have visited Earth many millennia ago to tamper with human evolution, that they were also responsible for our earliest known languages. In David’s case, this meant reconstructing the ancient tongue known as Proto-Indo-European.
Remember that scene in Prometheus when David, the ship’s AI, was studying ancient languages in the hopes of being able to speak to the Engineers? The logic here was that since the Engineers were believed to have visited Earth many millennia ago to tamper with human evolution, that they were also responsible for our earliest known languages. In David’s case, this meant reconstructing the ancient tongue known as Proto-Indo-European.
Given the fact that my wife is linguistics major, and that I love all things ancient and historical, I found the concept pretty intriguing – even if it was a little Ancient Astronauts-y. To think that we could trace words and meaning back through endless iterations to determine what the earliest language recognized by linguists sounded like. Given how many tongues it has “parented”, it would be cool to meet the common ancestor.
 And now there is a piece of software that can do just that. Thanks to a group of linguists and computer scientists in the US and Canada, this program has shown the ability to analyze enormous groups of languages to reconstruct the earliest human languages, long before there was writing. By using this program and others like it, linguists may one day know how people sounded when they talked 20,000 years ago.
And now there is a piece of software that can do just that. Thanks to a group of linguists and computer scientists in the US and Canada, this program has shown the ability to analyze enormous groups of languages to reconstruct the earliest human languages, long before there was writing. By using this program and others like it, linguists may one day know how people sounded when they talked 20,000 years ago.
Alexandre Bouchard-Côté, a University of British Columbia statistician, began working on the program when he was a graduate student at UC Berkeley. By using algorithms to compare sounds and cognates across hundreds of different modern languages, he found he could predict which language groups were most related to each other. Basically, a sound that remained the same across distantly-related languages most likely existed early in our linguistic evolutionary tree.
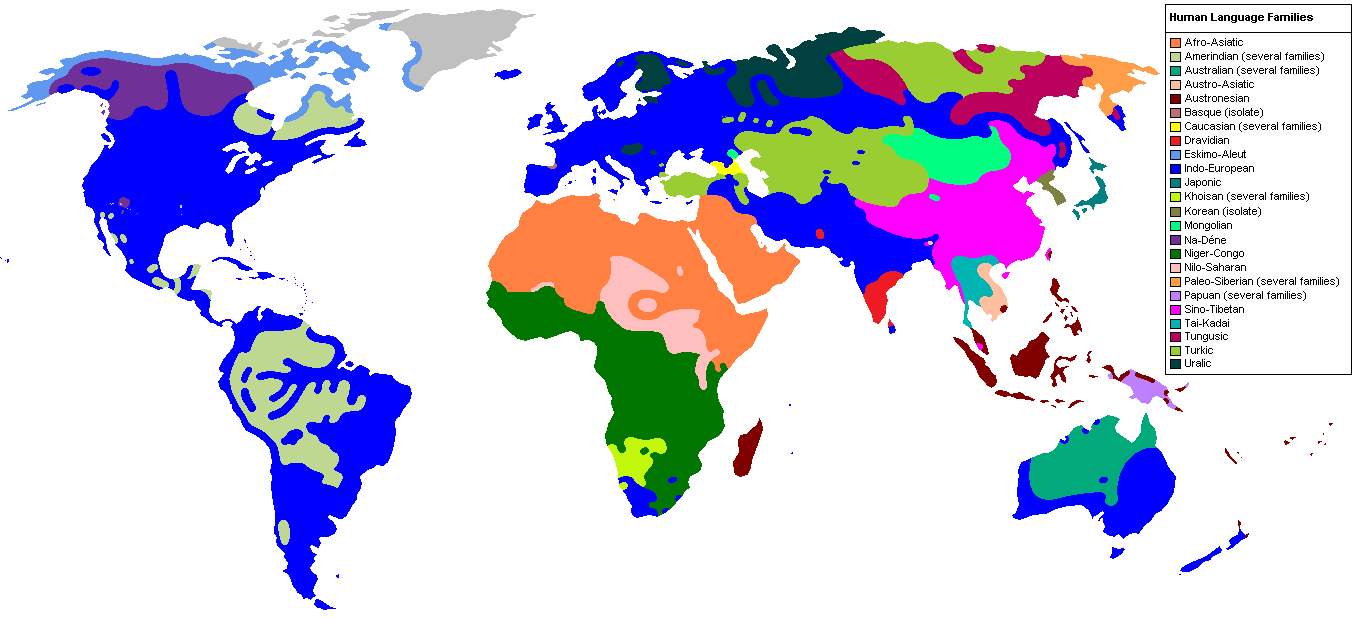 Modern linguists speculate that the earliest languages that led to today’s tongues include Proto-Indo-European, Proto-Afroasiatic and Proto-Austronesian. These are the ancestral language families that gave rise to languages like Celtic, Germanic, Italic and Slavic; Arabic, Hebrew, Cushite and Somali; and Samoan, Tahitian, and Maori. Though by no means the only language family trees (they do not account of Sub-Saharan Africa or the pre-Columbian Americas, for example), they do encompass the majority of spoken languages today.
Modern linguists speculate that the earliest languages that led to today’s tongues include Proto-Indo-European, Proto-Afroasiatic and Proto-Austronesian. These are the ancestral language families that gave rise to languages like Celtic, Germanic, Italic and Slavic; Arabic, Hebrew, Cushite and Somali; and Samoan, Tahitian, and Maori. Though by no means the only language family trees (they do not account of Sub-Saharan Africa or the pre-Columbian Americas, for example), they do encompass the majority of spoken languages today.
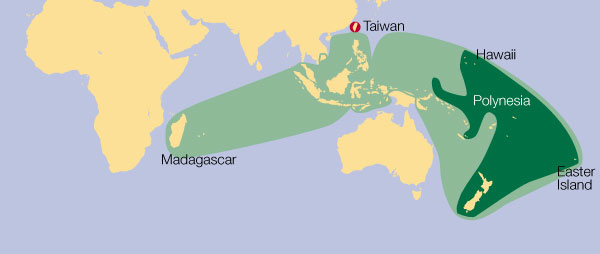
For their purposes, Bouchard-Côté and his colleagues focused on Proto-Austronesia, the family which led to today’s Polynesian languages as well as languages in Southeast Asia and parts of continental Asia. Using the software they developed, they were able to reconstruct over 600 ancient Proto-Austronesian languages and published their findings in the December issue of Proceedings of the National Academy of Sciences.
 In their paper, Bouchard-Côté and his researchers said this of their new program:
In their paper, Bouchard-Côté and his researchers said this of their new program:
“The analysis of the properties of hundreds of ancient languages performed by this system goes far beyond the capabilities of any previous automated system and would require significant amounts of manual effort by linguists.”
Ultimately, this program could allow linguists to hear languages that haven’t been spoken in millennia, reconstructing a lost world where those languages spread across the world, evolving as they went. In addition, it could be used for linguistic futurism, anticipating how languages may evolve over time and surmising what people will speak and sound like hundreds or even thousands of years from now.
Personally, I think the ability to look back and know what our ancestors sounded like is the real prize, but I’d be a poor sci-fi nerd if I didn’t at least fantasize about what our language patterns will sound like down the road. Lord knows its been speculated about plenty of times thus far, with thoughts ranging from Galego (a Slavic-English hybrid from Dune), the Chinese-English smattering used in Firefly, and City Speak from Blade Runner.
Hey, remember this little gem? Bonus points to anyone who can translate it for me (without consulting Google Translate!):
Monsieur, azonnal kövessen engem, bitte! Lófaszt! Nehogy már! Te vagy a Blade, Blade Runner! Captain Bryant toka. Meni-o mae-yo.

I might make use of software like that one day for a novel. Who knows?
There was a program on Project Genome (It may be called something different but similar) on which it was creating a genetic map of the world by doing dna tests on everyday people, all over the world. Most people in the world come off one branch of modern humans, but there is a tiny branch of people today that are genetically linked to a tiny population in Africa.
The reason I bring this up is that this tiny population has a very different language structure. While clicks and glottal stops are used here and there in various languages, their language uses more clicks, whistles, stops, and bird/animal sounds than any other human language. So in the end, the earliest language may not sound like a language at all to modern people. Other than if you listen to it long enough you start to hear repeated patterns and realize it is language and not sound.
The idea of being able to reverse engineer language isn’t new, and the program sounds fascinating. But I’m wondering at the likelihood of it working. One of the oldest European languages still in use, relatively intact due to extreme isolation is the Basque language which is very complex. And if there is one thing the Dane Law shows us is that people will start simplifying a language to its roots when two groups of people find themselves in constant close contact.
Reverse engineering takes the complex, breaks it down to the simple, to figure out how to recreate it but also to figure out just what it does and now it does it. But language doesn’t go from simple to complex. It seems to go from complex to simple. Seeking out these proto-languages is an interesting exercise and a curious diversion, but I’m not sure it will get us to any root language.
That’s true to a point, but languages have also shown the ability to become more refined and complex over time as well. This is usually the result of writing systems and language studies being introduced, not to mention class consciousness. High Latin, High German, Parisian French, Emperor’s Japanese, and Queen’s English are all examples of this.
And to believe that our earliest ancestors had a more complex language when they lacked the means to formalize it, i.e. were illiterate, is a bit of a stretch. Granted, there was likely to be greater diversity, but evidence suggests that languages like Proto-Indo-European tongue was much more uniform prior to roughly 4000 BC when divergence truly began.
As for Basque, it really is cool isn’t it? Linguists have already traced its foundations back to early Indo-European migrations and found similarities with modern Farsi, Hindi, and their ancestral Sanskrit. I loved hearing about it when my wife and I were in Basque country, so cool to think that there are cultures that pre-exist Latin and Gaelic conquests.
Post interesting, discussion enlightening.
I’ll say! Wouldn’t it be awesome to be able to speak in the language that gave birth to Sanskrit?
We robots are pretty smart!